Building an API in Go to Manage Files on Amazon S3

When I decided to create my blog, I chose Amazon S3 to host the images for my posts. The decision was practical (S3 is reliable, inexpensive, and scales well), but I also saw it as an opportunity: using a real, everyday problem to deepen my fluency in the AWS ecosystem, especially around security, automation, and integrations.
After creating a Go program that allows me to optimize and convert images to WebP, which I detailed in this article, I decided to build an API—also in Go—that allows me to manage my AWS account. With it, I can perform single or multiple file uploads, manage buckets, perform intelligent listings, and handle efficient streaming downloads.
That’s how this API came to life: a Go application that allows me to manage files and buckets in S3 with a productivity-focused workflow, supporting single and multiple uploads, paginated listings, streaming downloads, and the generation of temporary URLs (presigned URLs) for secure access.
To ensure agility in day-to-day usage, the application is fully containerized with Docker. This way, I spin up the container and use the endpoints (which I keep saved in Apidog). With each upload, I instantly receive the final file link, ready to paste into a blog post. This is exactly the “fast and easy” workflow I was aiming for.
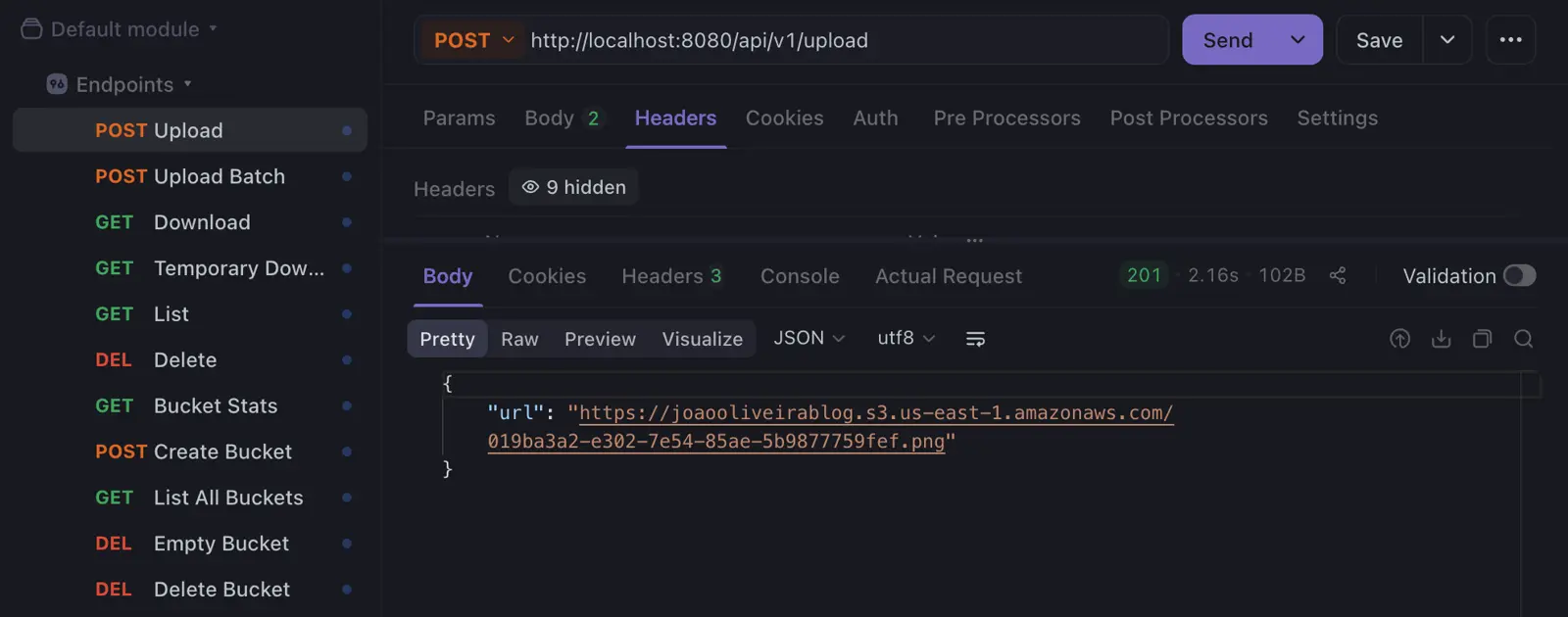
What This API Does
In short, this API covers:
- Single and multiple uploads (with concurrency).
- Paginated listing of objects with useful metadata.
- Streaming downloads, avoiding loading entire files into the API’s memory.
- Presigned URLs for temporary and secure access to private buckets.
- Bucket management (create, list, view statistics, empty, and delete).
Architecture and Project Structure
I structured the project following the recommendations of the Go Standards Project Layout. This organization, inspired by Clean Architecture, allows the application to start robustly while making it easier to evolve features and maintain the system over time.
How Each Part Connects
A simple way to understand the architecture is to imagine a flow:
- Handler (HTTP): translates the protocol, performs minimal validation, and returns the response.
- Service: applies business rules, validations, security, concurrency, and timeouts.
- Repository (interface): defines the storage contract.
- S3 Repository (implementation): handles integration details with the AWS SDK.
Directory Structure
s3-api/
├── .github/
│ └── workflows/ # CI: pipelines (tests, lint, build) with GitHub Actions
├── cmd/
│ └── api/
│ └── main.go # Bootstrap: loads config, initializes dependencies, starts the HTTP server
├── internal/
│ ├── config/ # Centralized configuration: typed env vars + defaults
│ ├── middleware/ # HTTP middlewares: logging, timeout, recovery, etc.
│ └── upload/ # Domain module (files and buckets in S3)
│ ├── entity.go # Domain entities and response DTOs
│ ├── errors.go # Domain errors (no HTTP coupling)
│ ├── repository.go # Storage contract (interface)
│ ├── s3_repository.go # Contract implementation using AWS SDK v2
│ ├── service.go # Business rules: validations, concurrency, timeouts
│ ├── handler.go # HTTP handlers: translate request/response and call the Service
│ └── service_test.go # Unit tests for the Service (with repository mocks)
├── .env # Local config (NEVER commit; use .gitignore)
├── Dockerfile # Multi-stage build (slim binary)
└── docker-compose.yml # Local environment: runs API with env vars and portsImportant Decisions in This Structure
cmd/api/main.go: This is where Dependency Injection is applied. Themainfunction creates the AWS client, the repository, and the service, wiring them together. If tomorrow we decide to replace S3 with a local database, we only need to change a single line here.internal/middleware/: This is where we implement structured logging middleware (usingslog) and a timeout middleware, ensuring that no request hangs indefinitely and protecting the overall health of the application.internal/upload/service.go: This is where we use advanced concurrency witherrgroup. When performing multiple uploads, the service launches several goroutines to communicate with S3 in parallel, drastically reducing response time.internal/upload/errors.go: Instead of returning generic strings, we use typed errors. This allows the Handler to elegantly determine whether it should return a400 Bad Requestor a404 Not Found.
Endpoints
The API is divided into two main groups: File management and Bucket management.
Files
| Method | Endpoint | Description |
|---|---|---|
| POST | /api/v1/upload | Upload a single file |
| POST | /api/v1/upload-multiple | Multiple upload |
| GET | /api/v1/list | Paginated listing |
| GET | /api/v1/download | Streaming download |
| GET | /api/v1/presign | Generate temporary (presigned) URL |
| DELETE | /api/v1/delete | Remove an object from the bucket |
Buckets
| Method | Endpoint | Description |
|---|---|---|
| GET | /api/v1/buckets/list | List account buckets |
| POST | /api/v1/buckets/create | Create bucket |
| GET | /api/v1/buckets/stats | Statistics |
| DELETE | /api/v1/buckets/delete | Delete bucket |
| DELETE | /api/v1/buckets/empty | Empty bucket |
Key Highlights and Technical Decisions
Decisions that have the greatest impact on real-world API usage.
UUID v7 for file names
For uploads, I use UUID v7 to rename files. In addition to avoiding collisions and preventing exposure of original names, v7 preserves temporal ordering. This helps with organization in S3, facilitates auditing, and leaves the door open for future evolution (for example, database indexing without losing order).
Streaming to avoid memory spikes
For downloads, the goal is to keep RAM usage stable. Instead of “downloading everything and then returning it,” I treat it as a stream: data flows from S3 directly to the client without becoming a large in-memory buffer inside the API.
Real file type (MIME) validation
File extensions are easy to spoof. For this reason, instead of trusting .jpg/.png, I validate the file content (header) to identify the actual type. This reduces the risk of uploading malicious content disguised as images.
Timeouts as resource protection
Since the API depends on external services (S3), I do not want requests to hang indefinitely. Timeouts prevent excessive consumption of goroutines and connections when the network is unstable or the provider is slow.
Initializing the Project
The first step is to prepare the development environment. Go uses the module system (go mod) to manage dependencies, ensuring that the project is reproducible on any machine.
# Create the root folder and enter the directory
mkdir s3-api && cd s3-api
# Initialize the module (replace with your repository if needed)
go mod init github.com/JoaoOliveira889/s3-api
# Create the directory tree following the Go Standard Project Layout
mkdir -p cmd/api internal/upload internal/config internal/middlewareDependency Management
I use the AWS SDK for Go v2 and a few libraries to make the project more robust (HTTP routing, env loading, UUIDs, testing). The goal is to keep the dependency set lean and well-justified, avoiding anything unnecessary.
# SDK core and configuration/credentials management
go get github.com/aws/aws-sdk-go-v2
go get github.com/aws/aws-sdk-go-v2/config
# S3 service client
go get github.com/aws/aws-sdk-go-v2/service/s3
# Gin Gonic: high-performance HTTP framework
go get github.com/gin-gonic/gin
# GoDotEnv: load environment variables from a .env file
go get github.com/joho/godotenv
# UUID: generate unique identifiers (v7)
go get github.com/google/uuid
# Testify: assertions and mocks for tests
go get github.com/stretchr/testifyDomain Layer
This is where the entities and contracts live. The core idea is: the domain describes what the system does, without being coupled to S3 itself.
Entities
Entities represent the main data structures of the application: files, listing metadata, bucket statistics, and pagination.
package upload
import (
"io"
"time"
)
type File struct {
Name string `json:"name"` // final object name in storage
URL string `json:"url"` // resulting URL after upload
Content io.ReadSeekCloser `json:"-"` // Content is not serialized to JSON because it represents the file stream
Size int64 `json:"size"`
ContentType string `json:"content_type"`
}
type FileSummary struct {
Key string `json:"key"` // full object key in S3
URL string `json:"url"`
Size int64 `json:"size_bytes"`
HumanReadableSize string `json:"size_formatted"`
Extension string `json:"extension"`
StorageClass string `json:"storage_class"`
LastModified time.Time `json:"last_modified"`
}
type BucketStats struct {
BucketName string `json:"bucket_name"`
TotalFiles int `json:"total_files"`
TotalSizeBytes int64 `json:"total_size_bytes"`
TotalSizeFormatted string `json:"total_size_formatted"`
}
type BucketSummary struct {
Name string `json:"name"`
CreationDate time.Time `json:"creation_date"`
}
type PaginatedFiles struct {
Files []FileSummary `json:"files"`
NextToken string `json:"next_token,omitempty"` // continuation token (pagination token)
}Repository Interface
The repository defines a storage contract. This way, the Service layer does not “know” it is S3. It only knows that there is an implementation capable of storing, listing, downloading, and deleting.
Note: by using streaming for uploads/downloads, the API avoids loading entire files into memory, keeping RAM usage much more predictable.
package upload
import (
"context"
"io"
"time"
)
// Repository defines the storage contract.
type Repository interface {
// Upload stores the file in the bucket and returns the final object URL.
Upload(ctx context.Context, bucket string, file *File) (string, error)
// GetPresignURL generates a temporary URL for secure downloads.
GetPresignURL(ctx context.Context, bucket, key string, expiration time.Duration) (string, error)
// Download returns a stream (io.ReadCloser) to enable streaming without loading everything into memory.
Download(ctx context.Context, bucket, key string) (io.ReadCloser, error)
// List returns a page of files using a continuation token.
List(ctx context.Context, bucket, prefix, token string, limit int32) (*PaginatedFiles, error)
// Delete removes a specific object from the bucket.
Delete(ctx context.Context, bucket string, key string) error
// CheckBucketExists verifies whether the bucket exists and is accessible.
CheckBucketExists(ctx context.Context, bucket string) (bool, error)
// CreateBucket creates a bucket (usually with prior validations in the Service layer).
CreateBucket(ctx context.Context, bucket string) error
// ListBuckets lists all buckets available in the account.
ListBuckets(ctx context.Context) ([]BucketSummary, error)
// GetStats aggregates bucket statistics.
GetStats(ctx context.Context, bucket string) (*BucketStats, error)
// DeleteAll removes all objects from the bucket.
DeleteAll(ctx context.Context, bucket string) error
// DeleteBucket deletes the bucket.
DeleteBucket(ctx context.Context, bucket string) error
}Infrastructure Layer
With the contract defined, I can create the concrete implementation that talks to AWS. The goal here is to translate the domain’s needs into calls to the AWS SDK v2.
package upload
import (
"context"
"fmt"
"io"
"path/filepath"
"strings"
"time"
"github.com/aws/aws-sdk-go-v2/aws"
"github.com/aws/aws-sdk-go-v2/service/s3"
"github.com/aws/aws-sdk-go-v2/service/s3/types"
)
type S3Repository struct {
client *s3.Client
region string
}
func NewS3Repository(client *s3.Client, region string) Repository {
return &S3Repository{
client: client,
region: region,
}
}
func (r *S3Repository) Upload(ctx context.Context, bucket string, file *File) (string, error) {
input := &s3.PutObjectInput{
Bucket: aws.String(bucket),
Key: aws.String(file.Name),
Body: file.Content, // stream: avoids loading the whole file into memory
}
_, err := r.client.PutObject(ctx, input)
if err != nil {
return "", fmt.Errorf("failed to upload: %w", err)
}
// Direct URL
return fmt.Sprintf("https://%s.s3.%s.amazonaws.com/%s", bucket, r.region, file.Name), nil
}
func (r *S3Repository) List(ctx context.Context, bucket, prefix, token string, limit int32) (*PaginatedFiles, error) {
input := &s3.ListObjectsV2Input{
Bucket: aws.String(bucket),
Prefix: aws.String(prefix),
ContinuationToken: aws.String(token),
MaxKeys: aws.Int32(limit),
}
// In the SDK, an empty token must be nil to avoid sending an invalid token.
if token == "" {
input.ContinuationToken = nil
}
output, err := r.client.ListObjectsV2(ctx, input)
if err != nil {
return nil, fmt.Errorf("failed to list objects: %w", err)
}
var files []FileSummary
for _, obj := range output.Contents {
key := aws.ToString(obj.Key)
size := aws.ToInt64(obj.Size)
files = append(files, FileSummary{
Key: key,
Size: size,
HumanReadableSize: formatBytes(size),
StorageClass: string(obj.StorageClass),
LastModified: aws.ToTime(obj.LastModified),
Extension: strings.ToLower(filepath.Ext(key)),
URL: fmt.Sprintf("https://%s.s3.%s.amazonaws.com/%s", bucket, r.region, key),
})
}
next := ""
if output.NextContinuationToken != nil {
next = *output.NextContinuationToken
}
return &PaginatedFiles{Files: files, NextToken: next}, nil
}
func (r *S3Repository) Delete(ctx context.Context, bucket, key string) error {
_, err := r.client.DeleteObject(ctx, &s3.DeleteObjectInput{
Bucket: aws.String(bucket),
Key: aws.String(key),
})
return err
}
func (r *S3Repository) Download(ctx context.Context, bucket, key string) (io.ReadCloser, error) {
output, err := r.client.GetObject(ctx, &s3.GetObjectInput{
Bucket: aws.String(bucket),
Key: aws.String(key),
})
if err != nil {
return nil, err
}
// Return Body as a stream so the handler can io.Copy directly to the response.
return output.Body, nil
}
func (r *S3Repository) GetPresignURL(ctx context.Context, bucket, key string, exp time.Duration) (string, error) {
// The presign client generates temporary URLs without making the object public.
pc := s3.NewPresignClient(r.client)
req, err := pc.PresignGetObject(ctx, &s3.GetObjectInput{
Bucket: aws.String(bucket),
Key: aws.String(key),
}, s3.WithPresignExpires(exp))
if err != nil {
return "", err
}
return req.URL, nil
}
func (r *S3Repository) CheckBucketExists(ctx context.Context, bucket string) (bool, error) {
_, err := r.client.HeadBucket(ctx, &s3.HeadBucketInput{Bucket: aws.String(bucket)})
if err != nil {
return false, nil
}
return true, nil
}
func (r *S3Repository) CreateBucket(ctx context.Context, bucket string) error {
_, err := r.client.CreateBucket(ctx, &s3.CreateBucketInput{Bucket: aws.String(bucket)})
return err
}
func (r *S3Repository) ListBuckets(ctx context.Context) ([]BucketSummary, error) {
out, err := r.client.ListBuckets(ctx, &s3.ListBucketsInput{})
if err != nil {
return nil, err
}
var res []BucketSummary
for _, b := range out.Buckets {
res = append(res, BucketSummary{
Name: aws.ToString(b.Name),
CreationDate: aws.ToTime(b.CreationDate),
})
}
return res, nil
}
func (r *S3Repository) DeleteBucket(ctx context.Context, bucket string) error {
_, err := r.client.DeleteBucket(ctx, &s3.DeleteBucketInput{Bucket: aws.String(bucket)})
return err
}
func (r *S3Repository) DeleteAll(ctx context.Context, bucket string) error {
out, err := r.client.ListObjectsV2(ctx, &s3.ListObjectsV2Input{Bucket: aws.String(bucket)})
if err != nil || len(out.Contents) == 0 {
return err
}
var objects []types.ObjectIdentifier
for _, obj := range out.Contents {
objects = append(objects, types.ObjectIdentifier{Key: obj.Key})
}
_, err = r.client.DeleteObjects(ctx, &s3.DeleteObjectsInput{
Bucket: aws.String(bucket),
Delete: &types.Delete{Objects: objects},
})
return err
}
func (r *S3Repository) GetStats(ctx context.Context, bucket string) (*BucketStats, error) {
out, err := r.client.ListObjectsV2(ctx, &s3.ListObjectsV2Input{Bucket: aws.String(bucket)})
if err != nil {
return nil, err
}
var totalSize int64
for _, obj := range out.Contents {
totalSize += aws.ToInt64(obj.Size)
}
return &BucketStats{
BucketName: bucket,
TotalFiles: int(len(out.Contents)),
TotalSizeBytes: totalSize,
TotalSizeFormatted: formatBytes(totalSize),
}, nil
}
func formatBytes(b int64) string {
const unit = 1024
if b < unit {
return fmt.Sprintf("%d B", b)
}
div, exp := int64(unit), 0
for n := b / unit; n >= unit; n /= unit {
div *= unit
exp++
}
return fmt.Sprintf("%.1f %cB", float64(b)/float64(div), "KMGTPE"[exp])
}Technical Highlights in the Infrastructure Layer
- Context (
context.Context): network operations respect cancellation and timeouts; if the request is dropped, unnecessary work and resource consumption are avoided. - Efficient pagination: essential for large buckets; clients can navigate results without overloading the API.
- Presigned URLs: temporary and secure access to private buckets without exposing them publicly.
- Data presentation: formatting sizes and metadata significantly improves the experience for API consumers.
Service Layer
This layer is responsible for orchestration: validations, business rules, timeouts, and concurrency.
One detail I particularly like here: the Service interface exposes what the application does, while the concrete implementation remains private, enforcing the use of a constructor (factory). This helps keep the design consistent and controlled.
package upload
import (
"context"
"fmt"
"io"
"log/slog"
"net/http"
"path/filepath"
"regexp"
"strings"
"time"
"github.com/google/uuid"
"golang.org/x/sync/errgroup"
)
type Service interface {
UploadFile(ctx context.Context, bucket string, file *File) (string, error)
UploadMultipleFiles(ctx context.Context, bucket string, files []*File) ([]string, error)
GetDownloadURL(ctx context.Context, bucket, key string) (string, error)
DownloadFile(ctx context.Context, bucket, key string) (io.ReadCloser, error)
ListFiles(ctx context.Context, bucket, ext, token string, limit int) (*PaginatedFiles, error)
DeleteFile(ctx context.Context, bucket string, key string) error
GetBucketStats(ctx context.Context, bucket string) (*BucketStats, error)
CreateBucket(ctx context.Context, bucket string) error
ListAllBuckets(ctx context.Context) ([]BucketSummary, error)
DeleteBucket(ctx context.Context, bucket string) error
EmptyBucket(ctx context.Context, bucket string) error
}
const (
uploadTimeout = 60 * time.Second
deleteTimeout = 5 * time.Second
maxBucketNameLength = 63
minBucketNameLength = 3
)
var (
// S3 bucket names follow DNS rules (min/max length and charset). The regex covers the general pattern.
bucketDNSNameRegex = regexp.MustCompile(`^[a-z0-9][a-z0-9.-]{1,61}[a-z0-9]$`)
// Allowlist: validates the actual file type (detected MIME) instead of trusting the extension.
allowedTypes = map[string]bool{
"image/jpeg": true,
"image/png": true,
"image/webp": true,
"application/pdf": true,
}
)
type uploadService struct {
repo Repository
}
func NewService(repo Repository) Service {
return &uploadService{repo: repo}
}
func (s *uploadService) UploadFile(ctx context.Context, bucket string, file *File) (string, error) {
ctx, cancel := context.WithTimeout(ctx, uploadTimeout) // prevents "hanging" requests in S3 calls
defer cancel()
if err := s.validateBucketName(bucket); err != nil {
return "", err
}
if err := s.validateFile(file); err != nil {
slog.Error("security validation failed", "error", err, "filename", file.Name)
return "", err
}
// UUID v7 preserves temporal ordering and avoids collisions/exposure of original names.
id, err := uuid.NewV7()
if err != nil {
slog.Error("uuid generation failed", "error", err)
return "", fmt.Errorf("failed to generate unique id: %w", err)
}
file.Name = id.String() + filepath.Ext(file.Name)
url, err := s.repo.Upload(ctx, bucket, file)
if err != nil {
slog.Error("repository upload failed", "error", err, "bucket", bucket)
return "", err
}
file.URL = url
slog.Info("file uploaded successfully", "url", url)
return url, nil
}
func (s *uploadService) UploadMultipleFiles(ctx context.Context, bucket string, files []*File) ([]string, error) {
// errgroup cancels the context if any goroutine fails.
g, ctx := errgroup.WithContext(ctx)
results := make([]string, len(files))
for i, f := range files {
i, f := i, f // avoids incorrect capture of loop variables
g.Go(func() error {
url, err := s.UploadFile(ctx, bucket, f)
if err != nil {
return err
}
results[i] = url
return nil
})
}
if err := g.Wait(); err != nil {
return nil, err
}
return results, nil
}
func (s *uploadService) GetDownloadURL(ctx context.Context, bucket, key string) (string, error) {
if err := s.validateBucketName(bucket); err != nil {
return "", err
}
// Presign is the recommended way to provide temporary access to private buckets.
return s.repo.GetPresignURL(ctx, bucket, key, 15*time.Minute)
}
func (s *uploadService) DownloadFile(ctx context.Context, bucket, key string) (io.ReadCloser, error) {
if err := s.validateBucketName(bucket); err != nil {
return nil, err
}
return s.repo.Download(ctx, bucket, key)
}
func (s *uploadService) ListFiles(ctx context.Context, bucket, ext, token string, limit int) (*PaginatedFiles, error) {
if err := s.validateBucketName(bucket); err != nil {
return nil, err
}
if limit <= 0 {
limit = 10
}
res, err := s.repo.List(ctx, bucket, "", token, int32(limit))
if err != nil {
return nil, err
}
if ext == "" {
return res, nil
}
var filtered []FileSummary
target := strings.ToLower(ext)
if !strings.HasPrefix(target, ".") {
target = "." + target
}
for _, f := range res.Files {
if strings.ToLower(f.Extension) == target {
filtered = append(filtered, f)
}
}
res.Files = filtered
return res, nil
}
func (s *uploadService) DeleteFile(ctx context.Context, bucket string, key string) error {
ctx, cancel := context.WithTimeout(ctx, deleteTimeout)
defer cancel()
if key == "" {
return fmt.Errorf("file key is required")
}
if err := s.validateBucketName(bucket); err != nil {
return err
}
return s.repo.Delete(ctx, bucket, key)
}
func (s *uploadService) GetBucketStats(ctx context.Context, bucket string) (*BucketStats, error) {
if err := s.validateBucketName(bucket); err != nil {
return nil, err
}
return s.repo.GetStats(ctx, bucket)
}
func (s *uploadService) CreateBucket(ctx context.Context, bucket string) error {
if err := s.validateBucketName(bucket); err != nil {
return err
}
exists, err := s.repo.CheckBucketExists(ctx, bucket)
if err != nil {
return err
}
if exists {
return ErrBucketAlreadyExists
}
return s.repo.CreateBucket(ctx, bucket)
}
func (s *uploadService) DeleteBucket(ctx context.Context, bucket string) error {
if err := s.validateBucketName(bucket); err != nil {
return err
}
return s.repo.DeleteBucket(ctx, bucket)
}
func (s *uploadService) EmptyBucket(ctx context.Context, bucket string) error {
if err := s.validateBucketName(bucket); err != nil {
return err
}
return s.repo.DeleteAll(ctx, bucket)
}
func (s *uploadService) ListAllBuckets(ctx context.Context) ([]BucketSummary, error) {
return s.repo.ListBuckets(ctx)
}
func (s *uploadService) validateBucketName(bucket string) error {
bucket = strings.TrimSpace(strings.ToLower(bucket))
if bucket == "" {
return ErrBucketNameRequired
}
if len(bucket) < minBucketNameLength || len(bucket) > maxBucketNameLength {
return fmt.Errorf("bucket name length must be between %d and %d", minBucketNameLength, maxBucketNameLength)
}
if !bucketDNSNameRegex.MatchString(bucket) {
return fmt.Errorf("invalid bucket name pattern")
}
if strings.Contains(bucket, "..") {
return fmt.Errorf("bucket name cannot contain consecutive dots")
}
return nil
}
func (s *uploadService) validateFile(f *File) error {
seeker, ok := f.Content.(io.Seeker)
if !ok {
return fmt.Errorf("file content must support seeking")
}
buffer := make([]byte, 512)
n, err := f.Content.Read(buffer)
if err != nil && err != io.EOF {
return fmt.Errorf("failed to read file header: %w", err)
}
// Reset the stream back to the beginning before upload.
if _, err := seeker.Seek(0, io.SeekStart); err != nil {
return fmt.Errorf("failed to reset file pointer: %w", err)
}
detectedType := http.DetectContentType(buffer[:n])
if !allowedTypes[detectedType] {
slog.Warn("rejected file type", "type", detectedType)
return ErrInvalidFileType
}
return nil
}Technical Highlights in the Service Layer
Concurrency with errgroup
In multiple uploads, I don’t upload files one by one. I trigger uploads in parallel and let errgroup manage cancellation: if one upload fails, the others are signaled to stop. In practice, the total time tends to be close to the slowest upload, rather than the sum of all uploads.
Security: file type validation
The validation reads a portion of the content to identify the actual file type, reducing the risk of malicious files with a “spoofed” extension.
Resilience: per-operation timeouts
Operations such as upload and delete have different characteristics; therefore, it makes sense to define distinct time limits to keep the API responsive and avoid stuck resources.
Encapsulation and dependency injection
The Service depends on a Repository. This makes the code highly testable: in tests, I can mock the repository without needing AWS.
Handler Layer
The Handler translates HTTP into the application domain: it extracts parameters, performs minimal validation, calls the Service, and returns JSON (or streaming in the case of downloads).
I chose Gin for its combination of performance, simplicity, and a rich middleware ecosystem.
package upload
import (
"errors"
"io"
"net/http"
"strconv"
"github.com/gin-gonic/gin"
)
type Handler struct {
service Service
}
func NewHandler(s Service) *Handler {
return &Handler{service: s}
}
func (h *Handler) UploadFile(c *gin.Context) {
bucket := c.PostForm("bucket")
fileHeader, err := c.FormFile("file")
if err != nil {
c.JSON(http.StatusBadRequest, gin.H{"error": "file field is required"})
return
}
openedFile, err := fileHeader.Open()
if err != nil {
c.JSON(http.StatusInternalServerError, gin.H{"error": "failed to open file"})
return
}
defer openedFile.Close()
file := &File{
Name: fileHeader.Filename,
Content: openedFile,
Size: fileHeader.Size,
ContentType: fileHeader.Header.Get("Content-Type"),
}
url, err := h.service.UploadFile(c.Request.Context(), bucket, file)
if err != nil {
h.handleError(c, err)
return
}
c.JSON(http.StatusCreated, gin.H{"url": url})
}
func (h *Handler) UploadMultiple(c *gin.Context) {
bucket := c.PostForm("bucket")
form, err := c.MultipartForm()
if err != nil {
c.JSON(http.StatusBadRequest, gin.H{"error": "invalid multipart form"})
return
}
filesHeaders := form.File["files"]
if len(filesHeaders) == 0 {
c.JSON(http.StatusBadRequest, gin.H{"error": "no files provided"})
return
}
var filesToUpload []*File
for _, header := range filesHeaders {
openedFile, err := header.Open()
if err != nil {
continue
}
filesToUpload = append(filesToUpload, &File{
Name: header.Filename,
Content: openedFile,
Size: header.Size,
ContentType: header.Header.Get("Content-Type"),
})
}
defer func() {
for _, f := range filesToUpload {
f.Content.Close()
}
}()
urls, err := h.service.UploadMultipleFiles(c.Request.Context(), bucket, filesToUpload)
if err != nil {
h.handleError(c, err)
return
}
c.JSON(http.StatusCreated, gin.H{"urls": urls})
}
func (h *Handler) GetPresignedURL(c *gin.Context) {
bucket := c.Query("bucket")
key := c.Query("key")
url, err := h.service.GetDownloadURL(c.Request.Context(), bucket, key)
if err != nil {
h.handleError(c, err)
return
}
c.JSON(http.StatusOK, gin.H{"presigned_url": url})
}
func (h *Handler) DownloadFile(c *gin.Context) {
bucket := c.Query("bucket")
key := c.Query("key")
stream, err := h.service.DownloadFile(c.Request.Context(), bucket, key)
if err != nil {
h.handleError(c, err)
return
}
defer stream.Close()
c.Header("Content-Disposition", "attachment; filename="+key)
c.Header("Content-Type", "application/octet-stream")
_, _ = io.Copy(c.Writer, stream)
}
func (h *Handler) ListFiles(c *gin.Context) {
limit, _ := strconv.Atoi(c.DefaultQuery("limit", "10"))
result, err := h.service.ListFiles(
c.Request.Context(),
c.Query("bucket"),
c.Query("extension"),
c.Query("token"),
limit,
)
if err != nil {
h.handleError(c, err)
return
}
c.JSON(http.StatusOK, result)
}
func (h *Handler) DeleteFile(c *gin.Context) {
err := h.service.DeleteFile(c.Request.Context(), c.Query("bucket"), c.Query("key"))
if err != nil {
h.handleError(c, err)
return
}
c.Status(http.StatusNoContent)
}
func (h *Handler) GetBucketStats(c *gin.Context) {
bucket := c.Query("bucket")
if bucket == "" {
c.JSON(http.StatusBadRequest, gin.H{"error": "bucket parameter is required"})
return
}
stats, err := h.service.GetBucketStats(c.Request.Context(), bucket)
if err != nil {
c.JSON(http.StatusInternalServerError, gin.H{"error": err.Error()})
return
}
c.JSON(http.StatusOK, stats)
}
func (h *Handler) CreateBucket(c *gin.Context) {
var body struct {
Name string `json:"bucket_name" binding:"required"`
}
if err := c.ShouldBindJSON(&body); err != nil {
c.JSON(http.StatusBadRequest, gin.H{"error": "valid bucket_name is required"})
return
}
if err := h.service.CreateBucket(c.Request.Context(), body.Name); err != nil {
h.handleError(c, err)
return
}
c.Status(http.StatusCreated)
}
func (h *Handler) ListBuckets(c *gin.Context) {
buckets, err := h.service.ListAllBuckets(c.Request.Context())
if err != nil {
h.handleError(c, err)
return
}
c.JSON(http.StatusOK, buckets)
}
func (h *Handler) DeleteBucket(c *gin.Context) {
if err := h.service.DeleteBucket(c.Request.Context(), c.Query("name")); err != nil {
h.handleError(c, err)
return
}
c.Status(http.StatusNoContent)
}
func (h *Handler) EmptyBucket(c *gin.Context) {
bucket := c.Query("bucket")
if bucket == "" {
c.JSON(http.StatusBadRequest, gin.H{"error": "bucket parameter is required"})
return
}
err := h.service.EmptyBucket(c.Request.Context(), bucket)
if err != nil {
c.JSON(http.StatusInternalServerError, gin.H{"error": err.Error()})
return
}
c.Status(http.StatusNoContent)
}
func (h *Handler) handleError(c *gin.Context, err error) {
switch {
case errors.Is(err, ErrInvalidFileType),
errors.Is(err, ErrBucketNameRequired):
c.JSON(http.StatusBadRequest, gin.H{"error": err.Error()})
case errors.Is(err, ErrBucketAlreadyExists):
c.JSON(http.StatusConflict, gin.H{"error": err.Error()})
case errors.Is(err, ErrFileNotFound):
c.JSON(http.StatusNotFound, gin.H{"error": err.Error()})
case errors.Is(err, ErrOperationTimeout):
c.JSON(http.StatusGatewayTimeout, gin.H{"error": "request timed out"})
default:
c.JSON(http.StatusInternalServerError, gin.H{"error": "an unexpected error occurred"})
}
}Technical Decisions in the Handler
- Multipart/form-data without “blowing up RAM”: I open the file as a stream, avoiding loading the entire content into memory.
- Download streaming: I create a “pipe” between S3 and the client. This makes it possible to support larger files with modest hardware.
- Centralized error handling: instead of scattering
if err != nilacross all routes, the Handler maps semantic domain errors to consistent HTTP status codes (400, 404, 409, 504, etc.).
The Entry Point (main)
The main function loads configuration, instantiates dependencies, and starts the server. This is where one of the most useful concepts for keeping projects healthy comes into play: dependency injection.
In practical terms: main creates the AWS client → passes it to the repository → passes it to the service → passes it to the handler. This keeps the system modular and easy to test.
package main
import (
"context"
"log/slog"
"os"
"time"
// Internal packages
appConfig "github.com/JoaoOliveira889/s3-api/internal/config"
"github.com/JoaoOliveira889/s3-api/internal/middleware"
"github.com/JoaoOliveira889/s3-api/internal/upload"
"github.com/gin-gonic/gin"
// External packages
configAWS "github.com/aws/aws-sdk-go-v2/config"
"github.com/aws/aws-sdk-go-v2/service/s3"
"github.com/joho/godotenv"
)
func main() {
_ = godotenv.Load()
cfg := appConfig.Load()
logger := slog.New(slog.NewJSONHandler(os.Stdout, nil))
slog.SetDefault(logger)
r := gin.New()
r.Use(middleware.RequestTimeoutMiddleware(cfg.UploadTimeout))
r.Use(middleware.LoggingMiddleware())
r.Use(gin.Recovery())
ctx := context.Background()
awsCfg, err := configAWS.LoadDefaultConfig(ctx, configAWS.WithRegion(cfg.AWSRegion))
if err != nil {
slog.Error("failed to load AWS SDK config", "error", err)
os.Exit(1)
}
s3Client := s3.NewFromConfig(awsCfg)
repo := upload.NewS3Repository(s3Client, cfg.AWSRegion)
service := upload.NewService(repo)
handler := upload.NewHandler(service)
api := r.Group("/api/v1")
{
api.GET("/health", func(c *gin.Context) {
c.JSON(200, gin.H{
"status": "healthy",
"env": cfg.Env,
"timestamp": time.Now().Format(time.RFC3339),
})
})
api.GET("/list", handler.ListFiles)
api.POST("/upload", handler.UploadFile)
api.POST("/upload-multiple", handler.UploadMultiple)
api.GET("/download", handler.DownloadFile)
api.GET("/presign", handler.GetPresignedURL)
api.DELETE("/delete", handler.DeleteFile)
buckets := api.Group("/buckets")
{
buckets.POST("/create", handler.CreateBucket)
buckets.DELETE("/delete", handler.DeleteBucket)
buckets.GET("/stats", handler.GetBucketStats)
buckets.GET("/list", handler.ListBuckets)
buckets.DELETE("/empty", handler.EmptyBucket)
}
}
slog.Info("server successfully started",
"port", cfg.Port,
"env", cfg.Env,
"region", cfg.AWSRegion,
)
if err := r.Run(":" + cfg.Port); err != nil {
slog.Error("server failed to shut down properly", "error", err)
os.Exit(1)
}
}Technical Highlights in main
- Structured logging: JSON logs are more useful for indexing and searching in tools such as CloudWatch, ELK, or Datadog.
- Chained middlewares: logging and global timeouts are applied consistently across all routes.
- Recovery: prevents a
panicfrom bringing down the entire API. - Grouping and versioning:
/api/v1makes it easier to evolve the API without breaking existing clients.
Security and configuration: managing credentials
For the API to communicate with AWS, it needs credentials. However, exposing keys in the code is a serious risk. For this reason, in local development I use environment variables (via .env), and in production the natural evolution is to use IAM Roles.
.env file (local development)
At the root of the project, we create the .env file. It is used to store server configuration and AWS secret keys.
Warning: This file must be included in your
.gitignore. Never commit your keys to GitHub or any other version control system.
# Server Settings
PORT=8080
APP_ENV=development
# AWS Configuration
AWS_REGION=us-east-1
AWS_ACCESS_KEY_ID=SUA_ACCESS_KEY_AQUI
AWS_SECRET_ACCESS_KEY=SUA_SECRET_KEY_AQUI
# Application Settings
UPLOAD_TIMEOUT_SECONDS=60Obtaining Credentials in the AWS Console (IAM)
Access keys are generated in IAM. For study purposes, you can use broad permissions, but the recommended approach is to follow the principle of least privilege and restrict access to only the required bucket and actions.
Step by step:
- Access IAM: In the AWS Console, search for “IAM”.
- Create a User: Go to Users > Create user.
- Configuration: Define a name (e.g.,
s3-api-manager). It is not necessary to enable access to the AWS Management Console for this user, as it will be used only via code. - Permissions (Principle of Least Privilege): Choose Attach policies directly.
- Note: For learning purposes, you may select AmazonS3FullAccess. In a real production scenario, the ideal approach is to create a custom policy that grants access only to the specific bucket you intend to use.
- Generate the Keys: After creating the user, click on the user name, go to the Security credentials tab, and look for the Access keys section.
- Creation: Click Create access key, select the “Local code” option, and proceed.
IMPORTANT: You will see the Access Key ID and the Secret Access Key. Copy and paste them into your
.envfile immediately, as the Secret Key will never be shown again.
Middlewares: observability and resilience
Middlewares are the right place for global behaviors: logging, timeouts, correlation, and protection. Instead of replicating these concerns per endpoint, I centralize them.
Structured logging
The log is written after the request finishes. This makes it possible to accurately record the status code and latency, making performance and error analysis much easier.
package middleware
import (
"log/slog"
"time"
"github.com/gin-gonic/gin"
)
func LoggingMiddleware() gin.HandlerFunc {
return func(c *gin.Context) {
start := time.Now()
path := c.Request.URL.Path
raw := c.Request.URL.RawQuery
c.Next()
if raw != "" {
path = path + "?" + raw
}
slog.Info("incoming request",
"method", c.Request.Method,
"path", path,
"status", c.Writer.Status(),
"latency", time.Since(start).String(),
"ip", c.ClientIP(),
"user_agent", c.Request.UserAgent(),
)
}
}Timeout control
In systems that depend on external services, leaving connections open indefinitely is risky. The timeout middleware cancels the request when it exceeds a defined limit, freeing up resources.
package middleware
import (
"context"
"net/http"
"time"
"github.com/gin-gonic/gin"
)
func RequestTimeoutMiddleware(timeout time.Duration) gin.HandlerFunc {
return func(c *gin.Context) {
ctx, cancel := context.WithTimeout(c.Request.Context(), timeout)
defer cancel()
c.Request = c.Request.WithContext(ctx)
finished := make(chan struct{}, 1)
go func() {
c.Next()
finished <- struct{}{}
}()
select {
case <-finished:
return
case <-ctx.Done():
if ctx.Err() == context.DeadlineExceeded {
c.AbortWithStatusJSON(http.StatusGatewayTimeout, gin.H{
"error": "request timed out",
})
}
}
}
}Technical Highlights in Middlewares
c.Next()at the right moment: ensures that logs capture the actual status code and real latency.selectand channels: a clear pattern to observe “completed vs. timed out,” maintaining control over the request lifecycle.- Structured logs: make it easier to build dashboards and alerts.
Unit Tests
One of the greatest benefits of this architecture is the ability to test business logic in isolation, without AWS and without an internet connection.
I use mocks to simulate the repository and focus on validating: bucket rules, file type validations, identifier generation, and error handling.
package upload
import (
"context"
"io"
"time"
"github.com/stretchr/testify/mock"
)
type RepositoryMock struct {
mock.Mock
}
func (m *RepositoryMock) Delete(ctx context.Context, bucket string, key string) error {
panic("unimplemented")
}
func (m *RepositoryMock) DeleteAll(ctx context.Context, bucket string) error {
panic("unimplemented")
}
func (m *RepositoryMock) DeleteBucket(ctx context.Context, bucket string) error {
panic("unimplemented")
}
func (m *RepositoryMock) GetStats(ctx context.Context, bucket string) (*BucketStats, error) {
panic("unimplemented")
}
func (m *RepositoryMock) ListBuckets(ctx context.Context) ([]BucketSummary, error) {
panic("unimplemented")
}
func (m *RepositoryMock) Upload(ctx context.Context, bucket string, file *File) (string, error) {
args := m.Called(ctx, bucket, file)
return args.String(0), args.Error(1)
}
func (m *RepositoryMock) Download(ctx context.Context, bucket, key string) (io.ReadCloser, error) {
args := m.Called(ctx, bucket, key)
if args.Get(0) == nil {
return nil, args.Error(1)
}
return args.Get(0).(io.ReadCloser), args.Error(1)
}
func (m *RepositoryMock) GetPresignURL(ctx context.Context, bucket, key string, expiration time.Duration) (string, error) {
args := m.Called(ctx, bucket, key, expiration)
return args.String(0), args.Error(1)
}
func (m *RepositoryMock) List(ctx context.Context, bucket, prefix, token string, limit int32) (*PaginatedFiles, error) {
args := m.Called(ctx, bucket, prefix, token, limit)
return args.Get(0).(*PaginatedFiles), args.Error(1)
}
func (m *RepositoryMock) CheckBucketExists(ctx context.Context, bucket string) (bool, error) {
args := m.Called(ctx, bucket)
return args.Bool(0), args.Error(1)
}
func (m *RepositoryMock) CreateBucket(ctx context.Context, bucket string) error {
args := m.Called(ctx, bucket)
return args.Error(0)
}Implementing Service Tests
In the service_test.go file, we focus on testing business rules: bucket name validation, UUID generation, and error handling.
package upload
import (
"context"
"strings"
"testing"
"time"
"github.com/stretchr/testify/assert"
"github.com/stretchr/testify/mock"
)
type readSeekCloser struct {
*strings.Reader
}
func (rsc readSeekCloser) Close() error { return nil }
func TestUploadFile_InvalidBucket(t *testing.T) {
mockRepo := new(RepositoryMock)
service := NewService(mockRepo)
result, err := service.UploadFile(context.Background(), "", &File{})
assert.Error(t, err)
assert.Empty(t, result)
assert.ErrorIs(t, err, ErrBucketNameRequired)
}
func TestUploadFile_Success(t *testing.T) {
mockRepo := new(RepositoryMock)
service := NewService(mockRepo)
ctx := context.Background()
content := strings.NewReader("\x89PNG\r\n\x1a\n" + strings.Repeat("0", 512))
file := &File{
Name: "test-image.png",
Content: readSeekCloser{content},
}
bucket := "my-test-bucket"
expectedURL := "https://s3.amazonaws.com/my-test-bucket/unique-id.png"
mockRepo.On("Upload", mock.Anything, bucket, mock.AnythingOfType("*upload.File")).Return(expectedURL, nil)
resultURL, err := service.UploadFile(ctx, bucket, file)
assert.NoError(t, err)
assert.NotEmpty(t, resultURL)
assert.Equal(t, expectedURL, resultURL)
mockRepo.AssertExpectations(t)
}
func TestGetDownloadURL_Success(t *testing.T) {
mockRepo := new(RepositoryMock)
service := NewService(mockRepo)
bucket := "my-bucket"
key := "image.png"
expectedPresignedURL := "https://s3.amazonaws.com/my-bucket/image.png?signed=true"
mockRepo.On("GetPresignURL", mock.Anything, bucket, key, 15*time.Minute).
Return(expectedPresignedURL, nil)
url, err := service.GetDownloadURL(context.Background(), bucket, key)
assert.NoError(t, err)
assert.Equal(t, expectedPresignedURL, url)
mockRepo.AssertExpectations(t)
}
Technical Highlights in Tests
- Test the rule, not the integration: the Service must be predictable; integrations are left for dedicated tests.
- Security validation reflected in tests: if the API validates MIME types, the tests must respect this to remain realistic.
errors.Isand semantic errors: this strengthens consistency and makes assertions easier and clearer.
Automation with GitHub Actions
On every push or pull request, the CI installs dependencies and runs tests. This keeps the main branch stable and reduces the risk of regressions.
Configuring the Workflow (go.yml)
The configuration file should be created at .github/workflows/go.yml. It defines the steps required to validate the health of the project.
# .github/workflows/go.yml
name: Go CI
on:
push:
branches: [ main, develop ]
pull_request:
branches: [ main ]
jobs:
test:
name: Run Tests
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v4
- name: Set up Go
uses: actions/setup-go@v5
with:
go-version: '1.25.5'
cache: true
- name: Install dependencies
run: go mod download
- name: Verify dependencies
run: go mod verify
- name: Run tests
run: go test -v -race ./...
Technical Highlights in Automation
- Race detector (
-race): important because there is concurrency (parallel uploads). - Dependency caching: speeds up builds and reduces execution time.
- Secure pipeline: since the Service is tested with mocks, the CI does not require AWS credentials.
Centralized Configuration
In small projects, it is common to scatter os.Getenv calls. As projects grow, this becomes technical debt: dependencies become implicit and hard to track.
Centralizing configuration creates a “single source of truth”: validation and typing at startup, and simple consumption throughout the rest of the codebase.
package config
import (
"os"
"strconv"
"time"
)
type Config struct {
Port string
AWSRegion string
UploadTimeout time.Duration
Env string
}
func Load() *Config {
return &Config{
Port: getEnv("PORT", "8080"),
AWSRegion: getEnv("AWS_REGION", "us-east-1"),
UploadTimeout: time.Duration(getEnvAsInt("UPLOAD_TIMEOUT_SECONDS", 30)) * time.Second,
Env: getEnv("APP_ENV", "development"),
}
}
func getEnv(key, defaultValue string) string {
if value, exists := os.LookupEnv(key); exists {
return value
}
return defaultValue
}
func getEnvAsInt(key string, defaultValue int) int {
valueStr := getEnv(key, "")
if value, err := strconv.Atoi(valueStr); err == nil {
return value
}
return defaultValue
}Semantic Errors
The Service should not return HTTP status codes. It should return errors that make sense within the domain, and the Handler decides the appropriate status. This keeps the domain reusable (HTTP today, gRPC tomorrow, CLI later).
package upload
import "errors"
var (
ErrBucketNameRequired = errors.New("bucket name is required")
ErrFileNotFound = errors.New("file not found in storage")
ErrInvalidFileType = errors.New("file type not allowed or malicious content detected")
ErrBucketAlreadyExists = errors.New("bucket already exists")
ErrOperationTimeout = errors.New("the operation timed out")
)Technical Highlights in Error Handling
- Domain-agnostic design: errors remain meaningful outside of HTTP.
- Robust comparison with
errors.Is: safer than comparing strings. - Consistency: stable and predictable messages for API consumers.
Containerization with Docker
Containerization ensures that the API runs the same way in any environment. Here I use a multi-stage build: compilation happens in an image with the toolchain, and the final runtime image is smaller and more secure.
Optimized Dockerfile
services:
s3-api:
build: .
ports:
- "8080:8080"
env_file:
- .env
restart: alwaysOrchestration with Docker Compose
The docker-compose.yml file simplifies application startup by managing ports and automatically loading our secrets file (.env).
# Stage 1: Build the Go binary
FROM golang:1.25.5-alpine AS builder
WORKDIR /app
# Copy dependency files
COPY go.mod go.sum ./
RUN go mod download
# Copy the source code
COPY . .
# Build the application with optimizations
RUN CGO_ENABLED=0 GOOS=linux go build -ldflags="-w -s" -o main ./cmd/api/main.go
# Stage 2: Create the final lightweight image
FROM alpine:latest
RUN apk --no-cache add ca-certificates
WORKDIR /root/
# Copy the binary from the builder stage
COPY --from=builder /app/main .
# Copy the .env file (optional, better to use environment variables in prod)
COPY --from=builder /app/.env .
EXPOSE 8080
CMD ["./main"]Technical Highlights in Docker
- SSL certificates: minimal images do not always include CA certificates; without them, HTTPS calls may fail.
- Slim binary: build flags reduce size and speed up deployment.
- Smart caching: copying
go.mod/go.sumbefore the source code helps Docker reuse layers efficiently.
Useful Commands
Tests
go test ./...Running the Project
go run cmd/api/main.goBuild the image and start the container in the background
# Build the image and start the container in the background
docker-compose up --build -d
# View application logs in real time
docker logs -f go-s3-api
# Stop and remove the container
docker-compose downConclusion
Building this management API for Amazon S3 was a practical way to combine a real need (automating my blog workflow) with solid learning (Go, AWS, security, observability, and architecture).
Project Links
Main GitHub Repository: This is the “living” repository, which may evolve and differ from what is described in this article.
Article Version Code: To see the project exactly as it was built and explained here, in a static state.
References
- Go Standard Project Layout: https://github.com/golang-standards/project-layout
- Clean Architecture (The Clean Code Blog): https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html
- AWS SDK for Go v2 – S3 Developer Guide: https://aws.github.io/aws-sdk-go-v2/docs/getting-started/
- Go Concurrency Patterns (Context Package): https://go.dev/blog/context
- Gin Web Framework: https://gin-gonic.com/docs/
- Testify – Testing Toolkit: https://github.com/stretchr/testify
- Google UUID Package (v7 support): https://github.com/google/uuid
- Errgroup Package (Concurrency): https://pkg.go.dev/golang.org/x/sync/errgroup
- Dockerizing a Go App: https://docs.docker.com/language/golang/build-images/
- GitHub Actions for Go: https://github.com/actions/setup-go